How Did We Improve An Algorithm Speed by 60 Times?

Recently, my mentee and I refactored a key algorithm in one of our projects, and we achieved a 60-time speed gain.
Problem
We need regenerate a Docx file based on the OCR result, aiming to match the original format.
However, the OCR result does not contain the font size, and the binding box type is not accurate.
Therefore, we need use the coordinates of each binding box to calculate the size of each binding box, then, we can get the average character size, using binding box size divided by the string length in this binding box. Finally, we could compare this average character size with the font size generated from Pillow lib to get an estimated font size.
Original Solution
The original solution did the calculation locally -- for each binding box, they calculated the average character size, and compared with the font size by Pillow lib by using the bisection. This process actually repeats thousands of time. The bigger document, the worse performance.
Even worse, they first parsed the strings in each binding box to words with str.split() in Python. This is an unnecessary step, but adds a lot of overhead to the overall process.
Fix 0
Before jumping in the fix, we need understand where the problem is. My mentee used debugging tool with break point in PyCharm to profile the code, which was not very efficient.
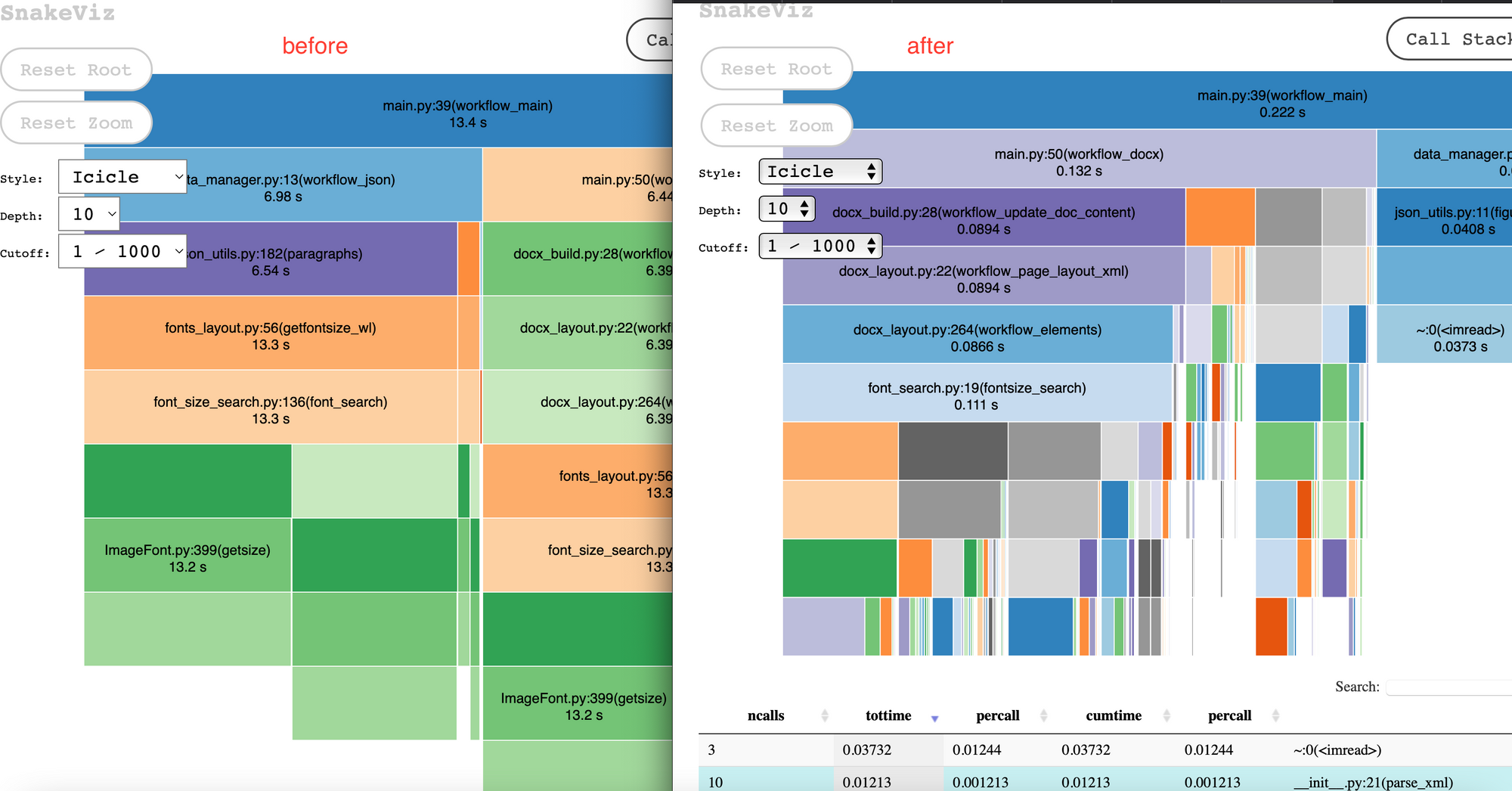
What I suggested is to use cProfile + SnakeViz to automatically profile code performance and visualize the profiling result.
Fix 1
My first suggestion to my mentee is to get rid of the paring method, and my reasoning is simple:
- We don't need the exact length of the characters (including space or punctuations).
- We can simply use the
str.len()to have the estimated length of the string in a particular binding box. - There might be some gaps between the estimated and exact length, but these gaps will not significantly impact the overall result, and we can add a threshold to reduce this impact.
Using a single str.len() to replace thousands of str.split() saves us a lot of time, and the result is close.
data["length"] = data['text']str.len()
Fix 2
The second suggestion I gave to my mentee is to get rid of the local bisection calculation. The assumptions are also straightforward:
- Each binding box with the same type should have the same font size, e.g. the all paragraph binding boxes should have the same font size;
- If we can get the font size of each type of binding box, we can apply them globally, and we don't need repeat the bisection procedure locally.
- Even though the binding box type might not be detected correctly, we can calculate the font size for these outliers locally.
Applying this strategy helped us to reduce thousands of bisection calculation to dozens.
def get_closests(df, col, val):
lower_idx = bisect_left(df[col].values, val)
return lower_idx
def get_font_size(value):
data = pd.DataFrame({"fontsize": FONT_AREA.keys(), "area": FONT_AREA.values()})
fontsize = get_closests(data, "area", value)
return round(fontsize*0.75)
Fix 3
The last suggestion I gave to my mentee is to use pandas to replace multiple for loops.
Since the data structure of the original design was quite complicated, involving multiple customized dictionaries, it was quite challenging to follow. With Pandas DataFrame, we can easily:
- visualize data to have a clearer understanding;
- use native vectorization to optimize processing speed;
- get rid of complicated foo loops;
- apply python function with
pandas.Series.apply(); - apply condition selection with
pandas.Series.where()orpandas.Series.mask()
Overall, this strategy further improves the processing speed.
def fontsize_search(dict):
data = pd.DataFrame(dict, columns=['element', 'text', 'width', 'height'])
data["length"] = data['text']str.len()
data["area"] = data['width'] * data['height']
data["size"] = data["area"] / data["length"]
data["fontsize"] = data["size"].apply(get_font_size)
return data["fontsize"].values.tolist()
Result
The result was encouraging: with the implementation by my mentee, we reduced the processing time from 12 sec to 0.22 sec in a sample document, a 60-time speed gain!
I am really proud of my mentee, and I am happier than if I implemented this by myself.
Takeaways:
- Delegating a key task to a junior member is both challenging and rewarding;
- A proper mentoring means that we need give proper space and help to our mentees. In this case, I first gave some general direction to my mentee and let her explore by herself. With some initial trials, I gave more specific suggestions to help her to go further. With more specific suggestions, I let her implement the algorithms by herself. Finally, I reviewed her code to make sure the quality.



Comments ()