How Did We Save Our Video Classifier Cost by 84%

A recent project in our team was to improve the computing efficiency of a deep-learning-based video classifier. After carefully tuning the models and migrating to Kafka, we successfully reduced the cost by 84%.
Background
When we received the request, the model team already developed a POC version of the video classifier:
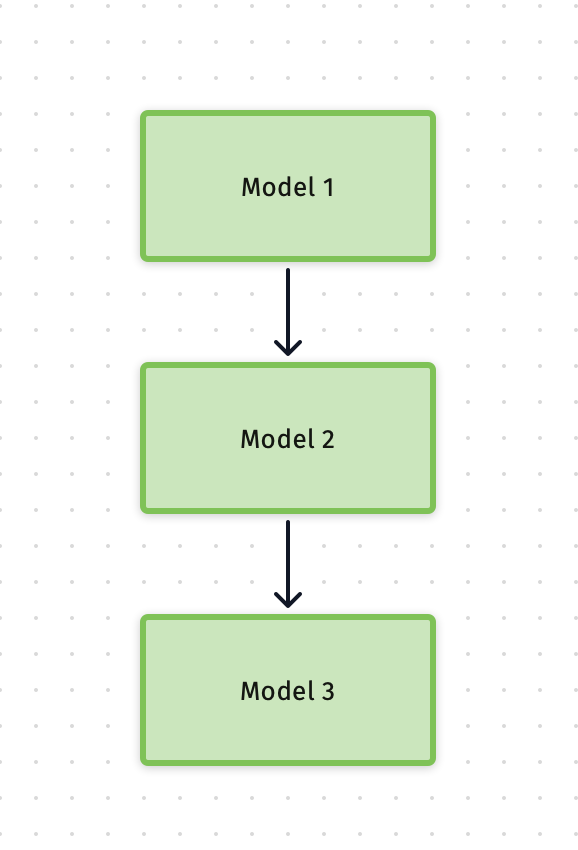
- The classifier has three models, and the POC version runs them in sequence, which costs 15 sec to run from end to end on average (on V100 GPU).
- The entire classier is wrapped a Docker image, consuming 15G GPU memory to run.
- The client asked to process at least 500,000 short video (smaller than 5MB) every day.
Based on these figures, we did some resource estimations:
- To process 500,000 short videos daily, with average processing time of 15 sec, the total computing time is 7,500,000 sec;
- Since each model node consumes 15G GPU memory during processing, so we can fit two nodes into one V100 GPU (32G memory);
- In total, we need 7,500,000/86,400/2 ≈ 44 V100 GPUs to support this request.
POC version
This POC version was to verify if the model pipeline works, so it didn't pay much attention to the processing speed. As we talked to the model owner, we had much better understanding:
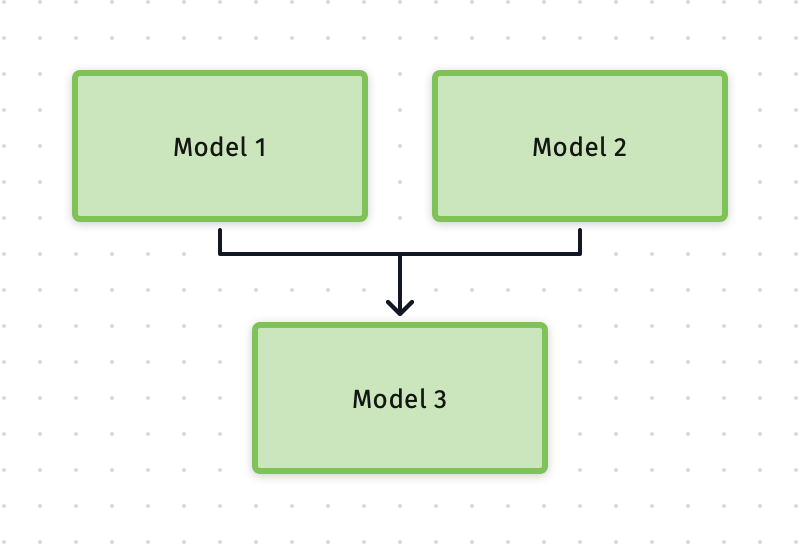
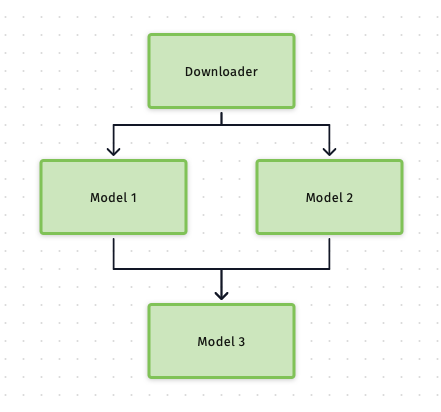
- Among the three models, Model 1 and Model 2 are independent to each other, and they can run in parallel, Model 3 needs the input from the first and second model to process;
- Each of them is a deep learning model, and the POC version doesn't enable the batch processing. Therefore, one classifier node can only process one video at any given time.
Based on these information, we asked if the model owner can provide us the speed benchmark of each model, so we may prepare a better architecture to improve the speed.
The benchmark came back as:
- Model 1: 4 sec
- Model 2: 6 sec
- Model 3: 5 sec
If we need run these three models together with the minimal waiting time, the deployment ration would be like this:
- Model 1: 15
- Mode 2: 10
- Model 3: 12
The First Fix
The first fix involved two sides: the deep learning model side, and the architecture side.
The deep learning side needs update their IO interface:
- each model needs to be optimised to improve the processing speed.
- it needs to enable batch processing and accept a list of videos as inputs. The preprocessing logic will sample certain amount of frames from the video, and if this number is smaller than the batch limit, then we can batch samples from multiple videos. In this way, we can process multiple videos at the same time.
Point 1 was handled by model team itself, and the second point was not easy to implement. Since we had prior experience to use BentoML library, we suggested to give a try.
One of the killer features in BentoML is Adaptive Micro Batching, and this is exact solution we needed in Point 2:
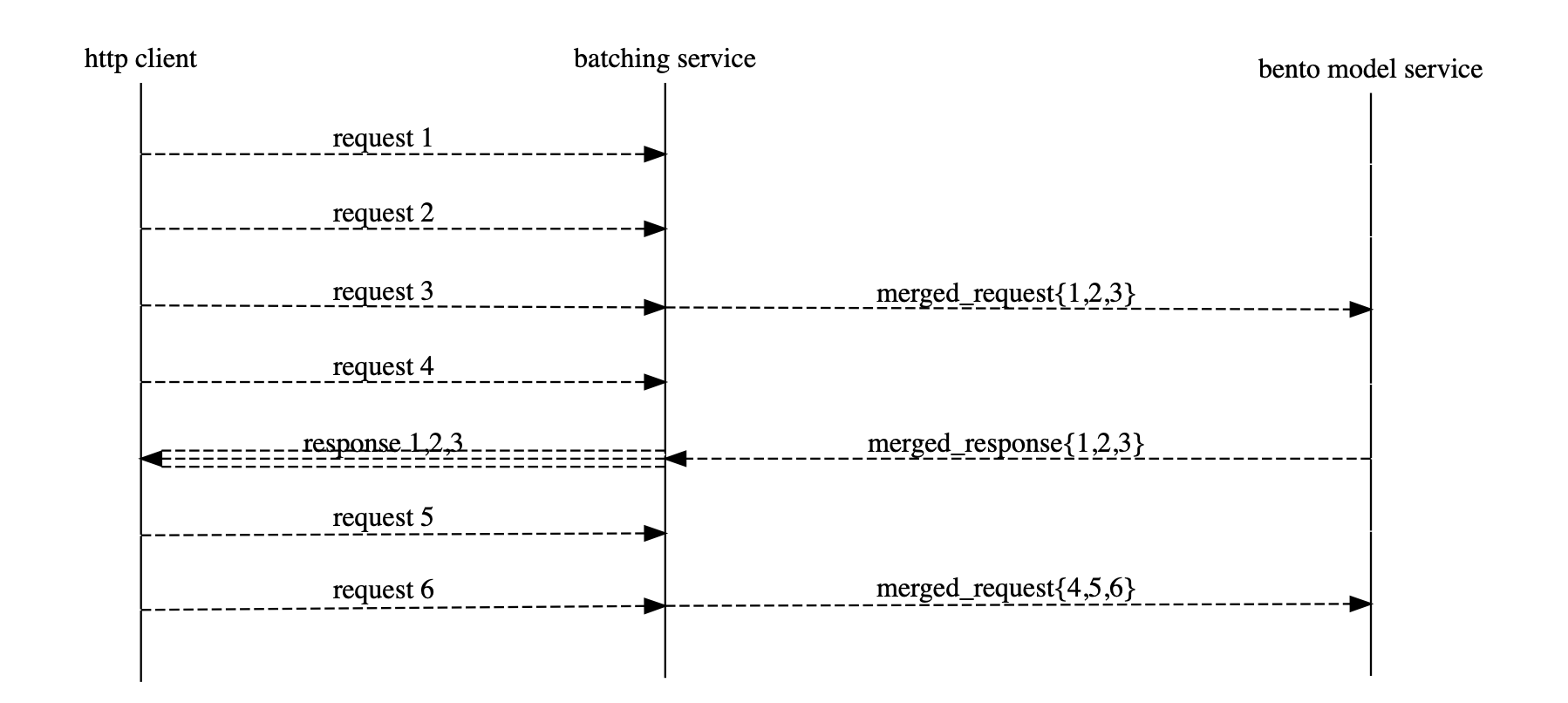
Therefore, we recommended this library to the model team, and on our side, we also deployed the Yatai by BentoML to improve deployment and serving experience.
Apart from using the BentoML to enable batch processing in GPU, we also discovered that each model has their own downloader, so the entire classifier downloads the same video data three times. We helped extracting the downloader from the model side, and coordinate them to consume the downloaded data from our internal file storage. With this implementation, we easily squeezed another 2 seconds from the original 15 sec.
We further tested if we shall compress the video data transferring between different models: if we compress, we need compress and decompress in each model, which adds mode overhead than sending the uncompress video data directly since our video file are pretty small. Therefore, we didn't include this implementation.
With the work from both sides, we had a significant reduction: the overall processing time was dropped from 15 sec to 5 sec on average. In other words, we can cut the GPU cost from 44 instances to 15 instances.
The Second Fix
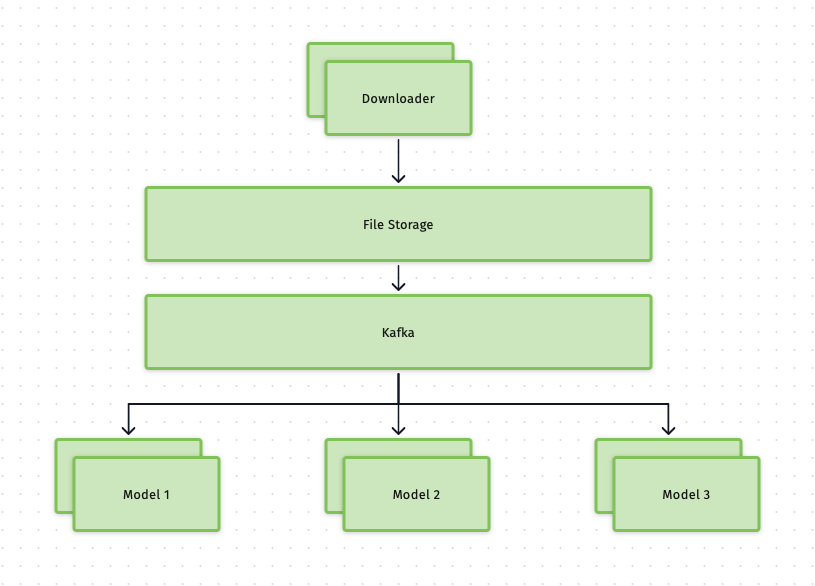
However, there is one more challenge here. The above design was based on the assumption that the requests would come in smoothly, but in the real production environment, there are some peaks hours that we would receive more requests than the usual time. To handle such a situation, we need a more stable architecture, then a pubsub system such as Kafka comes to our mind:
- We can use Kafka to handle the sudden traffic increase;
- Since we have different run time on each model, we can decouple individual models and deploy different numbers of nodes for each node.
- With individual model deployed separately, we can create relevant topics on Kafka, and let each model as consumers subscribe to them accordingly.
There is a tradeoff: BentoML 0.13 only supports RESTful API, but no Kafka support yet. If we switch to Kafka, we cannot use the adaptive batching in BentoML, and cannot use Yatai for deployment. If we stick with BentoML, we cannot have Kafka to support increasing traffic during peak hours. After talking to the core development of BentoML, they wouldn't provide Kafka support until they release BentoML 1.0. We evaluated both solutions throughout, and finally decided to choose Kafka instead of BentoML:
- The number of 500,000 daily requests is only the beginning, and we need consider the future upscaling;
- We have more video classifiers to develop, and each of video will be processed by all the classifiers.
- BentoML may support Kafka in later version, and if this happens, we can easily switch back to BentoML.
Therefore, we removed BentoML for this fix, and added batch processing logic by ourselves. We then modified the API interface to Kafka worker, so each model works as a consumer to Kafka. To further improve the Kafka architecture, we spent much time on tuning the parameters in Kafka, such as partition number, batch size of producer, compression type of producer and batch size of consumer. Finally, we found the best combination to use the least time to process incoming requests with minimal failures.
Result
With the above implementations, we achieved the best speed with the models running on two V100 instances: 2018 total running time on 1800 videos, which is 1.12s on average. How did we achieve this improvement?
- In the final design, we decoupled downloading tasks from the classification tasks, so the file storage and Kafka act as a buffer to handle all incoming requests. While the consumers -- nodes of 3 models are processing the videos stored in the file storage, the download can accept new requests and download them;
- Since all model nodes subscribe to the relevant Kafka topics, we can fully use the capacity of those GPU nodes, so there will be minimal idle time for these nodes;
- Also, since all models enabled batch processing, so they can process multiple videos at the same time as long as the number of the sampled frames smaller than the batch limit. This further increases the concurrency.
With these implementations, we can use 7 V100 GPU nodes to support 500000 daily requests, only 16% of the original planning.
Takeaways from this project:
- Any architecture design has its own advantage and disadvantage, so we need make trade off regarding specific business requirements;
- When we aim to improve the processing speed of a deep learning service, we can implement from model itself, and also from the service architecture level;
- Decoupling services not only adds flexibility to the entire service, but also let us run different services in parallel, which significantly reduces the overall running time.



Comments ()