DPS 周刊 201 - 一个月可能写五十万行代码?

过去一个月,我重新捡起了写代码,准确地说,我自己并没有写多少代码,绝大部分都由 AI 代劳。
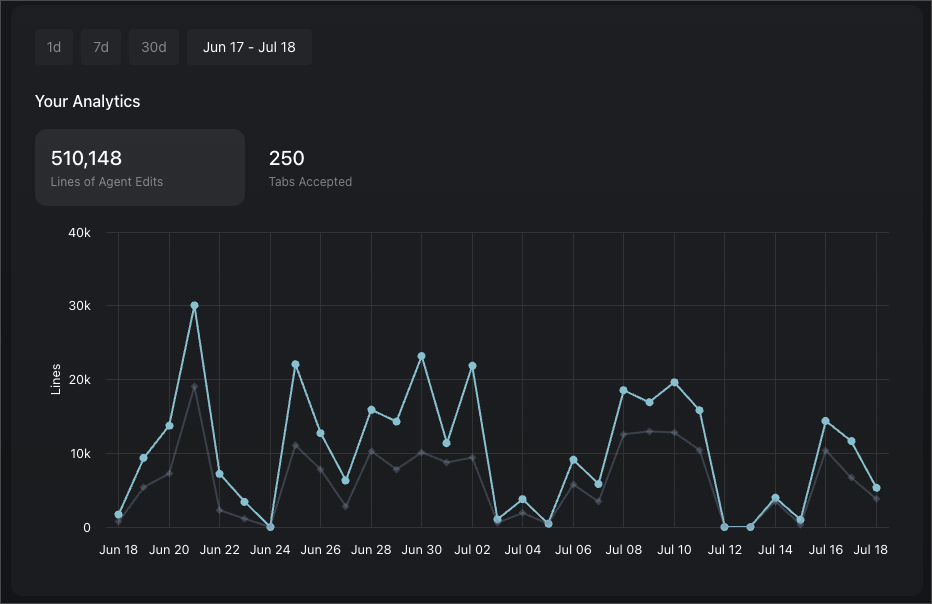
- 以上是 Cursor 的统计,一共生成了超过五十万行代码,平均下来,每天都超过一万行。这样的强度估计比我之前写的代码加起来都多;
- vibe coding 也好,context coding 也好,spec coding 也好,都只是不同的叫法,整体的体验就像是在大型策略类游戏。我可以从写代码的角色中脱离出来,更像是一个架构师,一步步指引这些工具写出需求。
- 目前看来最有效的策略是,
- 先给出一些简单的需求,然后让工具生成 PRD,requirements 和 todo。
- 然后仔细阅读这三个文档,把不需要的功能精简,把需要的功能加上去。
- 然后就让工具严格按照 todo 执行。每一步都要 git commit,看情况切换分支;
- 每一个需求实现之后都要求写单元测试,大的模块完成之后,再写更复杂的测试;
- 每一个大模块写完之后,都要工具进行抽象,降低复杂度,提高可读性。
- 我先后使用了 ChatGPT,Google Gemini,Cursor,ChatGPT Codex,Kiro,和 Claude 来生成代码:
- 以上是按照我使用的先后顺序排序。Google Gemini Pro 2.5 是第一个让我觉得 wow 的代码生成工具,这种震撼堪比当初第一次使用 ChatGPT;
- 目前看来效果最好的是 Claude,其次是 Cursor。
- Claude 的基本工作模式是收到 prompt 之后,先进行规划,然后严格按照它的规划工作,如果中间遇到其他支线问题,它会加入规划,然后再执行。结束这个支线任务之后,它会继续回到原先规划的主线上。基本上不需要人工干预。
- 当然 Claude 很贵。我目前购买的是最便宜的套餐,基本上每个小时都会遇到用量限制,平均不到半小时,最快的是十分钟就用完。看了下,基本上每小时的 quota 大概在 50k tokens。更要命的是,这个限制是动态的,有一次我被限制之后,四个小时后才恢复;
- 所以搭配着 Cursor 使用还不错,开了 Auto 模式之后,基本没有遇到 Cursor 的用量限制。大块的任务交给 Cursor,小修小补可以交给 Cursor;
- Amazon 的 Kiro 其实是很不错的概念。给定 prompt 之后,它会先生成详尽的 PRD,开发需求和开发计划。然后 Kiro 就会严格按照开发计划工作。其实这也是一般软件工程师的工作模式。只可惜 Kiro 现在只能调用 Claude 3.7 的模型,效果大打折扣。
- ChatGPT Codex 拿来做代码审核很不错,提交 prompt 之后,它会自动从 Github 拉取代码,然后执行 prompt。我经常出门前提交 prompt,让它以一个架构师的角度来审核整个项目。然后把它的建议丢给 Claude 或者 Cursor 去加工;
- 总体而言 Claude 和 Cursor 的代码生成质量不错。但是生成的时候,他们是直线思考,只会线性地生成,不太会抽象,不太会复用代码。所以经常需要指导他们去做抽象,去复用代码。否则项目会变得非常冗余。更关键的是,不错抽象的代码会耗费更多的 tokens,也就是更费钱费时间。所以 pruning 非常关键。
- 很多声音会觉得,这些工具的出现会让程序员这一职业变得没落,其实我倒是很乐观:
- 这些工具的出现,实际上解决了怎么写的问题,效率质量都比我自己写要高得多;
- 所以我的价值不在于怎么写,而在于写什么,如何写得更有价值;
- 如果没有这些工具,这个项目恐怕要写很久。我曾经试着重构一个重要功能,让 Claude 估算了一下,至少是一个熟练程序员两周的工作量,而我指导 Claude 写,不到半天就完成了;
- 对于初级程序员来说,这些工具也是好消息,因为可以大大加快学习进度。我在这一个月里学到的后端知识,比我前几年做 EM 学到的都多;
- 当然程序员的领域知识变得更加重要。很多工具都号称可以让一个令编程基础的人拿来编程。这话说得有一定道理,但是一个毫无经验的人拿这些工具写出来的代码,和一个有经验程序员拿这些工具写出来的代码,质量效率肯定都没法比。当然,不同人写代码有不同的需求,我们也不能拿一个模子来套用。
- 至少说,程序员这一职业并不会因为 AI 工具的诞生而消亡,反而因为这些开发成本被大大降低,会有更多的需求出现,会对程序员有更高的要求。
我们已经开通了微信支付和支付宝支付,如果你想及时读到 DPS 的全文,不妨直接付费订阅:
关于支付的详情介绍,可以访问这一页面。
Recap
Joan Westenberg 明白,时间不会积累,也不会再生。时间不能借出去收利息,只能用或者不用:
- 对她来说,成为“时间亿万富翁”始于一个前提:她的每一个小时,原本就属于她自己。只是她忘了,账户的主人是谁。
- 在金融领域,套利是利用市场失效来获利。而在生活里,时间套利就是用同样的方法,去利用注意力的差价。
- 每一个自动化的 SOP,每一个由虚拟助理管理的任务,每一次被委派的决定,都是时间套利。每一个明天不再需要她亲自做的决定,都是时间套利。
- 她明白,你没法在一个专门用来分散注意力的系统里,把效率优化到极致。唯一的做法,就是退出那个系统。
- 所谓“时间亿万富翁”,如 Graham Duncan 所说,就是生命中还剩十亿秒的人。这大约等于 31 年。

Pedro Tavares 发现,添加新软件的边际成本正在接近零,尤其是有了大语言模型(LLMs)。但理解、测试以及信任这段代码的代价呢?比以往任何时候都高。
- 他不确定,作者是否完全理解自己提交的内容。
- 他注意到,生成的代码引入了不熟悉的模式,或者打破了既有的惯例。
- 在他看来,真正的瓶颈过去是、现在依然是:代码审查、通过指导和结对编程进行知识传递、测试、调试,以及协调与沟通所带来的人力成本。
- 最终,他发现我们陷入了这样一种局面:代码生产变得更简单,但验证却更复杂,这并不一定让团队整体运转得更快。
- 他回忆,开发者们过去常常拿“复制粘贴工程师”开玩笑,但 LLM 所带来的速度与规模,却让这种复制粘贴的习惯被进一步放大。

Joan Westenberg 发现:高效,其实是深度的敌人。而所有有趣的事物,都藏在深度里。
- 她每周会留出整整一天,不使用 AI。
- 那一天,她坚持用自己大脑生成内容,用自己的语言表达,而不是依赖任何外部支架。
- 就在那时,她意识到自己一直缺失的东西:原创思考所带来的满足感。
- 现代生活让人习惯性地逃避这种状态。因此,坐在模糊与不确定里,不急于转移注意力,本身就是一种激进的自我找回。
- 每一条思路最终都走进了死胡同,或者落入陈词滥调。但这正是重点。她正在学习如何与一个问题待在一起,即使它迟迟不给答案。

Tiago Forte 的目标不是要在尝试的每件事上都成为专家,而是要高效地分辨出什么值得投入,什么不值得:
- 他认为,第一阶段是让自己在新的领域中建立方向感。他把自己的内容摄取时间看作一个需要主动配置的投资组合。
- 他会重新分配已有的内容摄取时间(不增加额外时间,只是把原本就花在其他内容上的时间引导过来)。
- 他领悟到一个关键点:仅仅是通过接触,他就会开始自动学习。他的大脑在不需要刻意思考的情况下,就会开始建立心理模型,识别出模式。
- 他会主动向别人征求推荐。他会在社交媒体上发帖寻求资源,或者向朋友圈打听。个人推荐往往是很强的信号,尤其当同一个名字被多次提到时。
- 他明白,最好的内容往往是人与人之间分享的,而不是算法推荐出来的。

Phil Schmid 认为真正的 AI 编程应该是上下文编程:
- 他引用 Tobi Lutke 的说法:“提示工程的艺术,在于为任务提供足够的上下文,使 LLM 有可能成功解决问题。”他认为 Tobi 说得很对。
- 随着智能代理(Agents)的兴起,加载到「有限工作记忆」中的信息,变得比以往更加重要。
- 他观察到,决定一个智能代理成功还是失败的关键,不再是模型本身,而是你为它提供的上下文质量。如今,大多数代理失败,原因不是模型失灵,而是上下文失误。
- 在他看来,廉价的演示和“神奇”代理之间的差距,就在于你提供的上下文质量。
- 在他的理解中,代码的主要任务,不是去“思考如何回应”,而是去“收集 LLM 为达成目标所需要的信息”。

Dan Koe 认为,想要变得富有,唯一的办法就是:(1)把自己的时间价值定在一个近乎妄想的高额时薪;(2)对变富这件事抱有执念;(3)不给自己任何退路,除了变富。
- 他很早就意识到,自己无法接受每天辛苦工作 8-10 个小时,只为了每年赚 8 万到 15 万美元,在一份毫无归属感、也毫不关心的工作里卖命,尤其是当他清楚看到,有人能做着有意义的工作,花更少的时间,却能赚到百倍的收入。
- 那些无休止地将金钱道德化、精神化的人,根本无法想象一种生活:那就是自己不再被金钱所束缚。
- 设定一个理想化的高时薪,其真正目的就在于:促使自己做出更好的决策,并训练大脑去捕捉那些能让自己置身更高杠杆位置的机会。
- 如果你设定的理想时薪没有让你感到“不可能”,那说明定得还不够高——他是这样认为的。
- 每一个专注投入的瞬间,都是在重新塑造大脑,以与自己想成为的人更接近。

Calvin French-Owen 刚刚离开 OpenAI,他回顾了在这家公司的经历:
- 几乎所有在领导岗位的人,如今都在做和 2-3 年前完全不同的工作。
- 当公司规模快速扩张时,所有事情都不可避免地会“崩坏”。
- OpenAI 并不存在一种统一的“OpenAI 体验”,因为研究、应用和市场(GTM)运作在截然不同的时间节奏上。
- OpenAI 有一个很特别的地方:所有事情,真的是所有事情,都在 Slack 上完成,公司里根本没有邮件。
- OpenAI 的文化 极其自下而上,尤其在研究领域。

Philipp Schmid 介绍道,在 USB 等标准出现之前,连接外部设备需要各种各样不同的接口和自定义驱动程序。同样,把 AI 应用程序集成到外部工具和系统中,也曾是一个“M×N 问题”。
- MCP 的目标是通过提供一个通用 API,将这个问题简化为“M+N 问题”。工具开发者只需要为每个系统构建 N 个 MCP 服务器,而应用开发者则只需为每个 AI 应用构建 M 个 MCP 客户端。
- MCP 服务器是 MCP 世界和外部系统具体功能(API、数据库、本地文件等)之间的桥梁或接口。它们本质上是封装器,用于根据 MCP 规范暴露这些外部能力。
- MCP 客户端是宿主应用(比如 IDE、聊天机器人等)的一部分,用于管理与特定 MCP 服务器的通信。
- 任何“开放标准”都应该有一份规范,而 MCP 就拥有一份非常优秀的规范。他指出,仅凭这份规范,就打败了很多没有详细规范的竞争者。
- Anthropic 并没有从零开始重新发明一切,而是借鉴了 Language Server Protocol(LSP),例如 JSON-RPC 2.0。

Andrew Bosworth 认为开发产品并不是单纯的创造之旅,而是发现用户需求的旅程:
- 在最近与电影导演詹姆斯·卡梅隆的一次对话中,他提出了一个有趣的观点:电影制作人所进行的实验过程,与其说是在发明讲故事的方式,不如说是在探索观众更容易(或更不容易)投入到故事中的方式。
- 他们亲眼见证并切身感受到了这些成功实验的效果,于是越来越多的电影人开始效仿,并在此基础上尝试新东西,电影语言因此变得更丰富、更深刻。
- 人类并非都是一模一样的,他怀疑我们对讲故事的接受度,在整个群体中可能比对任何特定工具的自然倾向更具有普遍性,所以他并不想暗示所有产品都存在一个尚待发现的“理想形态”。
- 但归根结底,这些能力最终都是用来探索消费者的偏好。
- 如今,他所在的团队会使用“用户旅程”来确保他们的产品对于目标用户有清晰的定位:是谁在使用产品,他们有什么问题,以及产品将如何帮助他们。

Maalvika Bhat 认为创造不是诞生,而是谋杀——是为了可能之事而谋杀不可能之事:
- 所谓“品味与技能的差距”指的是:你的品味(识别品质的能力)往往比你的技能(创造品质的能力)发展得更快。这种差距就是 Ira Glass 所说的“那道鸿沟”,它也正是创作者与消费者之间的分水岭。
- 我们大多数人之所以停止画画,并不是因为缺乏天赋,而是因为判断的能力先于执行的能力出现了。
- 但人类的创造力要求我们在“可以想象的”和“实际能做到的”之间跋涉。这是一种诅咒,也是祝福:我们拥有完美的幻象,也拥有向着它不断失败前进的能力。
- 卓越来源于对不完美的亲密感,精通建立在与失败的熟识之上,通往完美之作的路径,恰恰是大量不完美之作的累积。
- 当你想象实现目标时,大脑中负责奖赏的神经回路会像你真正完成目标时一样被激活。这种现象在神经科学中被称为“目标替代”。

Archive
本周的生产力日报集合就到此为止,如果你有什么建议,也欢迎留言告诉我们。如果想要收到最及时的推荐,不妨订阅我们的频道,或者付费解锁更多增值内容,我们下期见。
如果你喜欢的话,不妨直接订阅这份电子报 ⬇️



Comments ()